GitHub Actions Self-hosted runner を Google Compute Engine で構築する
GitHub Actions を利用する際には、デフォルトで利用できる GitHub-hosted runner を利用することが多いでしょう。しかし、特定のユースケースにおいては、独自に用意したインフラストラクチャ上で実行される Self-hosted runner を利用する必要が出てきます。
このページでは、まず最初に Self-hosted runner についての一般的な前提知識を述べます。次に、Webhook を利用したシンプルでスケーラブルなアーキテクチャの概要を示し、Google Cloud におけるその具体的な実装例について解説します。
以降、単に runner と表記した場合、Self-hosted runner を表すものとします。
Self-hosted runner の種類 #
Self-hosted runner には運用上の差がある 3 種類があります。
- Normal runner
- 従来から利用できる最も基本的な runner です。
- 登録および解除は registration token または remove token を利用した明示的な操作で行います。
- 他の手法と異なり、runner は原則として複数のジョブを実行できるように常駐して受け付ける形で運用します。
- 補足: このページでは他の種類と区別するために便宜上 Normal と呼称しますが、ドキュメントに記載のある名前ではありません。
- Ephemeral runner
- Normal runner の特殊な形態で、登録手段は同じですが、単一のジョブを完了した時に自動的に登録が解除されるという差分があります。
- Runner が再利用されないためセキュリティ上の利益があります。
- 再利用できないため、ジョブごとに動的に runner をプロビジョニングする何らかの仕組みが必要です。
- 上記の特性はとりわけ runner をコンテナベースのインフラ (Docker, Kubernetes) で運用する場合に有用です。
- ただし、この目的の場合は次の JIT runner が上位互換であり、よりシンプルな構成ができるため推奨されます。
- 言い換えると、JIT runner に対する Ephemeral runner の利点は、Normal runner の運用基盤を流用することができる点と言えるでしょう。
- Just-In-Time (JIT) runner
- 最も新しい種類の runner で、基本的な性質は Ephemeral runner と同様です。
- 登録には registration token ではなく専用の JIT configuration を生成して利用します。
- Ephemeral runner との重大な差分として、runner の登録パラメーター (group や labels など) は JIT configuration を生成する段階で決定されるため、runner には生成済みの JIT configuration のみを渡して起動する形にできれば、runner 側からこうしたパラメータを変更できないように制限できます。
- これは一般に安全ではないコードが実行されうる runner に渡される情報の特権性が相対的に低くなるというセキュリティ的な利点といえます。
また、これら runner の登録スコープとして次の 3 種類があります。
- Repository runner
- 単一の repository でのみ利用できる runner です。
- Repository runner の登録には、適切な permission を持つ fine-grained access token (PAT, IAT, UAT) または classic PAT が利用できます。
- Organization runner
- ある organization と、配下のすべての repository で共用して利用できる runner です。
- Organization runner の登録には、適切な permission を持つ fine-grained access token (PAT, IAT, UAT) または classic PAT が利用できます。
- Enterprise runner
- ある enterprise と、配下のすべての organization, repository で共用して利用できる runner です。
- Enterprise runner の登録には classic PAT のみしか利用できないという制限があります。
Normal runner を複数リポジトリで利用できるように運用する場合、organization または enterprise スコープに登録するのが運用上は楽でしょう。Ephemeral / JIT runner はジョブごとにプロビジョニングする前提であるので、どのスコープに登録しても最終的に得られる結果に大きな差はありません。ただし、runner group など管理上の機能を利用する場合には organization または enterprise スコープに登録する必要があります。結論として、organization または enterprise のうち、要件に適合するスコープを選んで登録するのがよいでしょう。
Self-hosted runner の構成パターン #
運用観点から考えると、runner を提供するインフラの主要な構成パターンとして次のものが考えられます。
- A. 固定の数の runner を常駐させる
- シンプルな構成で、Normal runner を 1 台以上配置し、これを静的に登録しておくパターンです。
- 利点
- 登録は最初の一度きりであるため、手動で登録操作 を行うことにすれば、他のパターンにあるような特別な仕組みを構成する必要はありません。
- 構築・運用難易度が低いです。
- 十分な runner が待機していれば、ジョブの起動にかかるレイテンシーが小さいです。
- 欠点
- ジョブの需要とは無関係に常時起動するコンピューティングリソースがあり、たとえばこれをクラウド等で構築した場合、インスタンス料金を主とした固定費が生じ、ジョブの頻度次第ではコストパフォーマンスが低くなります。
- 事前に構築した runner 数をジョブの需要が上回った場合、ジョブの待機時間が増加します。あるいは runner 数を増減させるオペレーションが必要になります。
- B. ジョブ需要に基づいて runner 数を自動的に増減させる
- A の欠点を解消するため、オートスケーリングの仕組みを実装して、何らかの方法でジョブ需要を検知し、必要とされた時だけ、必要とされた量の runner を起動するパターンです。
- Normal runner を利用する場合には、ジョブ需要を適当な数値として表現し、それを runner 台数のスケーリング指標として用いる形になるでしょう。
- Ephemeral runner または JIT runner を利用する場合には、ジョブ待機数が 0 になるまで runner を起動し続ける、といった形になるでしょう。
- 利点
- ジョブ需要が短期的に増加した場合にも、(スケーリングできる範囲で)ジョブの待機時間を短く維持することができます。
- ジョブ需要に基づいた必要な runner 数のみがプロビジョニングされるため、コストパフォーマンスを高めることができます。特に、ジョブ需要がない状態で runner 数をゼロにする実装にした場合、固定費の大幅な削減が期待できます。
- 欠点
- ジョブ需要を検知する仕組み、および、それに基づいて runner 台数を変化させる仕組みを実装する必要があります。結果、構成は少し複雑です。
- Ephemeral / JIT runner の場合、ジョブに対して 1:1 で runner が必要なため、レイテンシーを最適化するにはより多くのリソースを確保する必要があります。
- A の欠点を解消するため、オートスケーリングの仕組みを実装して、何らかの方法でジョブ需要を検知し、必要とされた時だけ、必要とされた量の runner を起動するパターンです。
B において「ジョブ需要を検知する」具体的なアプローチとしては、以下のものが知られています。
- Webhook を利用する
- Webhook は、GitHub 上のさまざまなイベントに対応して外部システムを呼び出す仕組みです。
- 利用可能なイベントの一つである workflow_job (action=queued) は、ジョブの起動に伴い呼び出されます。
- (a) 直接的には、このイベントは単一のジョブ需要に対応していて、イベントを受信するごとに Ephemeral runner または JIT runner を起動すればよいでしょう。
- このアプローチはイベントドリブンでステートレスであり非常に見通しが良いです。
- (b) より進んだ実装としては、イベントを“キュー”に格納して、これを非同期的に消費するワーカーで、Ephemeral runner または JIT runner を起動する方法です。
- 1-a の課題は、runner の起動に失敗した時のリトライ処理、runner の上限/下限といったスケーリングポリシー、などステートフルな実装を直接するのが難しいことです。
- イベントをキューに格納してバッファリングした上で、定期的に起動するワーカーが runner を正常に起動するごとにキューからイベントを取り除くようなアーキテクチャにすることで、上記のような点を実装に組み込むのが容易になるでしょう。
- (c) Normal runner を利用する場合、1-b におけるキューの長さをジョブ待機数の指標とみなしてスケーリングアルゴリズムを実装することができるでしょう。
- ただし、この場合は workflow_job (action=completed) イベントも受信して、キューを減少させるといったことが追加で必要です。
- 指標が得られればよいので、実装上は“キュー”である必要はなく単純なカウンターでもよいでしょう。
- ジョブ需要の直接的なメトリクスを得る
- GitHub Actions Runner Controller (ARC) がこの方法を採用しています。
- 公開情報として知られている GitHub API に直接的に「ジョブ需要」を得るものは存在しません。
- ARC では未公開の API を利用して (参考) この「ジョブ需要」を取得し、これに基づいて Kubernetes の Pod を JIT runner として起動するオートスケーリングアルゴリズムを実装しています。
- ARC は Kubernetes の存在を前提としているため、クラウドで構築する場合には GKE, EKS などを用意するのが基本となり一定の固定費用が生じてしまい、コスト面ではワークロードに見合っているか判断が必要です。
- ARC 以外では、1-c のように間接的に指標を得ることになるでしょう。
- GitHub Actions Runner Controller (ARC) がこの方法を採用しています。
小規模なワークロードの場合や実装および運用規模を小さく維持したい場合には、1-a が適しているでしょう。1-a でカバーできないような大規模なワークロードや、複雑なスケーリングポリシーを適用したい場合には、1-b, 1-c も検討できるでしょう。ただし、1-b, 1-c を独自に実装およびメンテナンスするのはコストがかかるため、ARC を最初から検討しても良いかもしれません。
以降では 1-a のアプローチを具体的に検討します。
Webhook ベースのシンプルなアーキテクチャ #
Webhook は設定できるスコープにいくつかの種類があります。
- Repository/Organization/Enterprise webhook
- それぞれ、対応するスコープに含まれるリポジトリのイベントを一括して受信することができます。
- 基本的には、runner の登録スコープに対応したスコープの webhook を利用するのがよいでしょう。
- ただし、repository runner を複数リポジトリに対して構成したい場合、個別リポジトリで webhook を設定するのは手間なため、より上位スコープの webhook か、GitHub App webhook を利用するのがよいでしょう。
- GitHub App webhook
- GitHub App webhook は GitHub App がインストールされたすべてのリポジトリのイベントを一括して受信することができます。
- 特に、Organization, Enterprise でイベント対象スコープを絞りたい場合には選択肢となるでしょう。
- また、後述する認証情報として IAT を利用する場合には GitHub App が存在するので、その GitHub App の webhook を利用するのが自然でしょう。
- なお、GitHub App webhook を利用する場合は、GitHub App 側で該当イベントを購読する明示的な設定と、必要な App 権限の付与が必要です。
また、webhook とはあまり関係ない一般論ですが、runner を登録するために GitHub API へリクエストを送る際の認証情報として、次のいずれかが必要になります。
- Fine-grained Personal Access Token (PAT)
- Classic PAT と比較して権限スコープを制限したトークンを作成できるものです。
- PAT を利用する場合はこちらが推奨されます。
- Classic Personal Access Token (PAT)
- Fine-grained PAT 以前から利用できていた従来の PAT は便宜上 classic と呼称されます。
- 権限スコープが広く、セキュリティ上は非推奨です。
- ただし、Enterprise runner の登録にはこの種類の認証情報のみが利用できます。
- GitHub App Installation Access Token (IAT)
- App が API 操作を行うのに利用される最も基本的な認証情報です。
- PAT と異なり短期クレデンシャルであり、最も狭い権限スコープを構成可能なため、セキュリティ上の安全性も相対的に高く推奨されます。
- GitHub App User Access Token (UAT)
- UAT は主に GitHub App がユーザーの代理として API 操作を行うために利用するものです。
- Runner の登録に関しては誰が行っても差分がないため、IAT と比較した UAT の利点は無く、セキュリティ的な意味ではより可能な操作の少ない IAT が推奨されます。
上記の 2 観点の選択肢の違いは、セットアップ手順のほか、実装で容易に吸収できる細部の差にとどまるため、いずれの構成を仮定しても一般性を失わないでしょう。ただし、最終的には次のパターンが実践的には選択されるでしょう:
- Enterprise runner: Enterprise webhook + Classic PAT
- Organization / Repository runner: App webhook + IAT
Enterprise については検証環境を持っていないためこれ以上は議論しません。後述の実装例は Organization/Repository スコープを前提としています。次に示す具体的な実装例では、後者で述べた構成を採用しています。
Google Cloud での実装例 #
terraform-module-simple-gha-runner-gce は、Google Cloud 上にシンプルな Self-hosted runner のためのインフラを構築する実装例です。モジュールを利用した実際の構築手順は README を参照してください。以下では簡単な解説にとどめます。
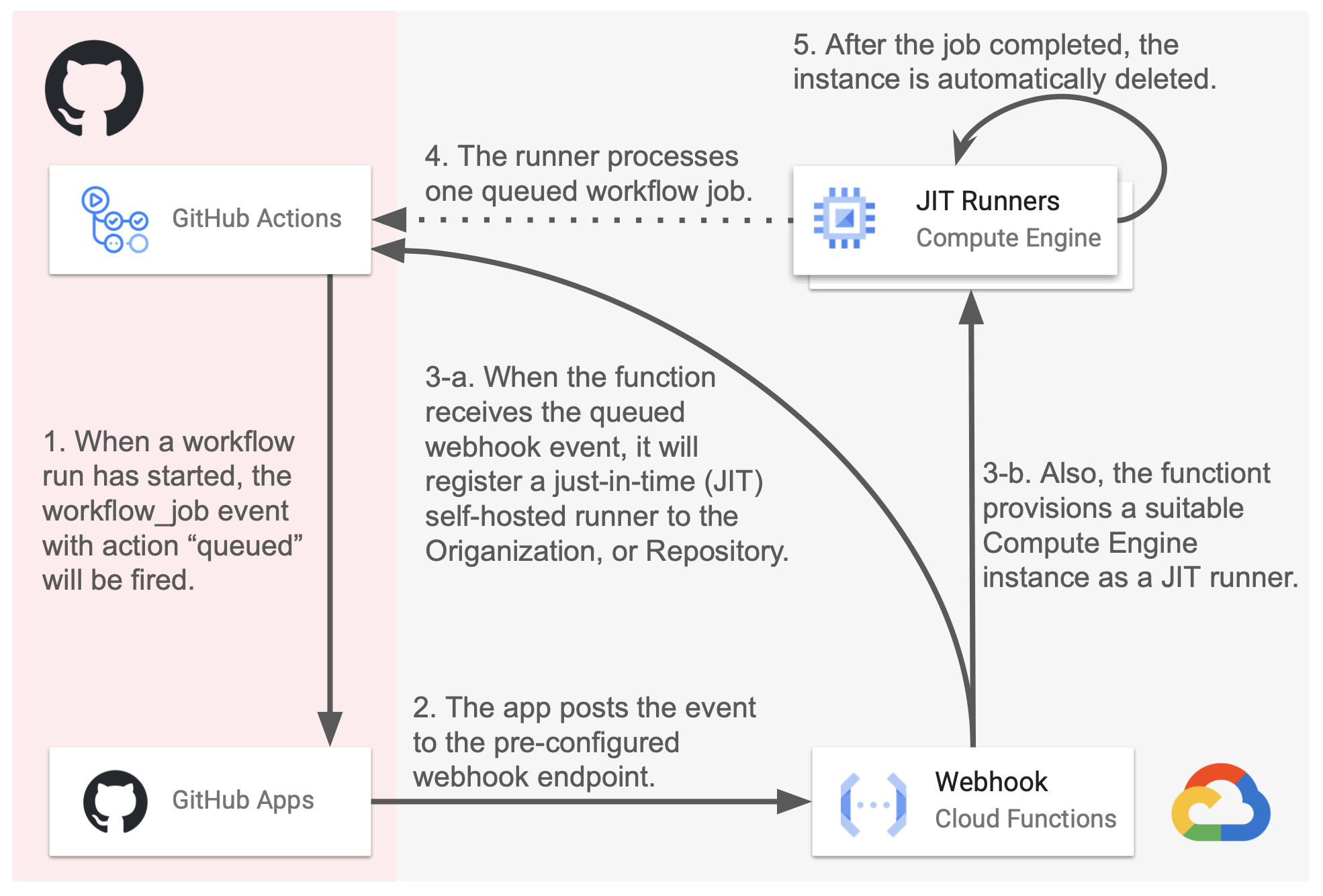
terraform-module-simple-gha-runner-gce のアーキテクチャ
GitHub App webhook を利用し、GitHub App がインストールされたリポジトリにおけるジョブ要求を監視します。イベントを受信するエンドポイントは Cloud Run functions でホストされています。Runner は Compute Engine インスタンスで提供される JIT runner です。
- この構成の長所
- ジョブごとに JIT runner をプロビジョニングするため、原理的にゼロスケールする
- Compute Engine バックエンドの範囲で無制限にスケールアウト可能であり、インスタンス構成の柔軟性も高い
- 固定費はゼロであり、非常に低コストで運用可能である (ゼロスケール可能性, Spot VM を活用するなど)
- イベント受信時の手続き
- GitHub から送信されたペイロードの署名検証
- 公開エンドポイントとする必要があるので、認証の代わりとして webhook secret に基づく適切な署名検証が重要です。
- ジョブが要求したラベルに基づく Compute Engine インスタンステンプレートの選択
- イベントペイロードには、ワークフローで要求したラベル の情報が提供されます。
- このモジュールでは複数の runner 構成に対応させるため、構成ごとにインスタンステンプレートを用意し、これをラベルと対応させています。
- サポートしている範囲では machine type, provisioning model (on-demand or spot) が構成可能です。
- 複数ラベルを要求した場合、すべてのラベルを持つ runner を要求するという GitHub 側の仕様に注意が必要です。
- 複数の構成にマッチした場合、この実装では最初に見つかった構成が選択されます。
- GitHub App の IAT の生成
- JIT configuration を生成する API を呼び出すため、GitHub App としての認証情報である IAT を取得します。
- JIT configuration の生成
- 選択された構成に基づいて API を呼び出し、JIT configuration を生成します。
- Runner の登録スコープは organization または repository で、事前に構成して (
runner_scope) 分岐します。登録先はイベントペイロードから推定されます。
- Compute Engine インスタンスの起動
- JIT configuration はメタデータとして渡され、起動スクリプトで JIT runner として実行されます。
- ジョブの実行が終了すると、インスタンスは自動的に削除されます。
- 厳密に言うと、実行が終了した時点では停止され、最長実行時間として指定した時間 (
instance_max_run_duration_seconds) が経過するとインスタンスが削除されます。
- 厳密に言うと、実行が終了した時点では停止され、最長実行時間として指定した時間 (
- GitHub から送信されたペイロードの署名検証
このモジュールは概念実装として具体例を示すために用意したものであり、非常に簡素化されています。実用上は、次のような点で拡張が必要でしょう。
- インスタンスのソースイメージには Debian を利用しています。このイメージには GitHub Actions ランナーとして要求されるツールがあまりインストールされていません。
- たとえば、典型的な用途の一つであるコンテナイメージのビルドに必要な Docker ランタイムがインストールされていません。
- 起動スクリプトを編集してインストールする、この runner の利用を前提にワークフローでインストールする、などの方法が考えられます。
- あるいは、様々なツールを起動スクリプトでインストールするとジョブ開始までの遅延が増えるため、あらかじめインストール済みのカスタムイメージを作成しておくのが効率的でしょう。
- (参考) Docker ランタイムなどをあらかじめインストールしたイメージを作成する例 (Packer)
- ラベルに基づく選択アルゴリズムは最も簡単なものになっており、優先度の処理や複雑な選択ロジックをを追加で実装する必要があるかもしれません。
- 構成パターンで議論した 1-a のアプローチにおける欠点のとおりで、起動に失敗した場合のリカバリーが実装されていません。この場合には、GitHub からジョブを手動で停止し、再度トリガーする操作でリトライする必要があります。
まとめ #
Self-hosted runner を構築するにあたって前提となる以下のような観点を整理しました。
- Normal / Ephemenral / JIT runner
- Runner の登録スコープ (Enterprise / Organization / Repository)
- Runner 登録に必要な認証情報 (classic PAT, fine-grained PAT, IAT, UAT)
- オートスケーリングのためのジョブ需要検知の手法 (Webhook, ARC)
また、Webhook ベースのシンプルなアーキテクチャを提案し、具体例として Google Cloud 上に構築する再利用可能な Terraform モジュールを紹介しました。今回提案した手法は小規模な環境に対しては十分に実用的で運用もしやすいと考えていますが、より大規模な条件においては ARC を念頭に検討するのがよいでしょう。